
Představujeme: Nový blog pro Kooperativu od FG Forrest
Seznamte se s naším dalším projektem pro pojišťovnu Kooperativa. Tentokrát jde o blog „Bezpečnost má zelenou“.
Stabilita e-shopů, webových stránek nebo intranetů našich zákazníků je pro nás nejvyšší prioritou. Spoléhají na nás značky jako Skupina ČEZ, Kooperativa nebo třeba SENESI a naše řešení tomu musí odpovídat. V našem novém článku zjistíte, jaké nástroje a procesy k tomu v FG Forrest používáme.

Ve svém portfoliu máme řadu velkých projektů pro významné firmy. Jedná se o řešení, u kterých může i ten nejkratší výpadek způsobit nemalé ztráty na obratu (v případě e-shopů) nebo pošramocení prestiže (u webových řešení). Proto jsme si v FG Forrest nastavili vlastní systém kontroly, který nás okamžitě upozorní na jakýkoliv zádrhel.
Pro interní monitoring používáme hned několik nástrojů. Některé pro nízkoúrovňový dohled nad IT komponenty (servery a služby, které web pro svůj běh potřebuje), jiné pro vyšší úroveň dohledu nad událostmi v aplikacích.
Icinga slouží pro monitoring na IT úrovni. Sleduje dostupnost serverů (ping, SSH – Secure Shell) a jejich služeb (www server, aplikační server, databáze, dostupnost WS – Web Services, třetích stran apod.), případně jejich základních metrik (využití disku, CPU apod.)
Detekované výpadky dostává IT oddělení e-mailem. Výpadky produkčních serverů a jejich služeb navíc i v SMS. Může tak okamžitě reagovat a obratem problém vyřešit.
Prometheus je perspektivní software pro sběr metrik ze serverů, jejich služeb a aplikací.
Ze serveru se sbírají metriky o využití jeho zdrojů – CPU, RAM, disků apod. Ze služeb se sbírají jejich vnitřní diagnostické informace (např. u Java jde o využití interních paměťových oblastí, režie mechanismu uvolňování paměti.)
Z aplikací Edee.one pak různé aplikační metriky, které umožňují vyhodnotit funkci a vytížení jejich vnitřních modulů i nestandardní situace, které v nich mohou nastat.
Příklady aplikačních metrik, které se stále rozšiřují:
Pro prezentaci sesbíraných metrik se používá software Grafana. IT oddělení a vývojářům poskytuje grafy jednotlivých metrik včetně jejich historického vývoje. Jejich analýzou je možné vyhodnocovat fungování jednotlivých komponent (serverů, služeb a aplikací), vyhodnocovat vzniklé problémy a vhodně na ně reagovat. Například navýšením zdrojů serveru, úpravou konfigurace jeho služeb nebo úpravou aplikací.
Částečně umožňuje některým problémům proaktivně předcházet. Např. lineární regresí predikovat vývoj obsazení disku a navýšit ho dříve, než dojde k jeho zaplnění.
Součástí nástroje Prometheus je i tzv. Alertmanager. Ten umožňuje definovat podmínky, které se nad sbíranými metrikami pravidelně vyhodnocují. Splnění podmínky znamená spuštění poplachu a odeslání upozornění IT oddělení a vývojářům.
V FG Forrest jsme si definovali několik podmínek nad aplikačními metrikami, které odesíláme do jednotlivých projektových kanálů v interním komunikačním nástroji Mattermost. Naši vývojáři se tak mohou hned pustit do práce na řešení.
Například:
Ač se to může na první pohled zdát, vytížení CPU není vhodný indikátor zatížení serveru a jeho správného dimenzování. Velmi záleží na typu provozované aplikace – „statický“ obsahový web, e-shop nebo specializovaná aplikace.
Na některých serverech při pozorovatelném zpomalení odezev aplikace není CPU nijak extrémně vytížené, což typicky signalizuje problémy s omezenými zdroji (thread / connection pool) nebo synchronizací (zámky). Po analýze problému vývojáři pak dojde k navýšení konfiguračních parametrů nebo optimalizaci aplikace, která problém vyřeší.
V jiných případech dochází ke zpomalení odezev aplikace až při vytížení CPU nad 90 %. I tato situace vyžaduje analýzu vývojářů a obvykle se řeší tzv. snížením konfiguračních parametrů (thread pool), které umožňují paralelně vykonávat mnoho operací najednou . V delším horizontu pak dochází k podrobnější analýze (profiling) a hloubkové optimalizaci některých procesů v aplikaci a opětovnému navýšení konfiguračních parametrů.
Vývoj obsazení disku také nelze spolehlivě použít pro predikci potřeby navýšení diskové kapacity. Třeba u e-shopů velmi záleží na způsobu aktualizace dat. Některé e-shopy mohou měsíce pomalu růst, aby pak během jednoho dne skokově vyčerpaly veškeré zbývající volné místo a vynutily si tak neodkladné navýšení.
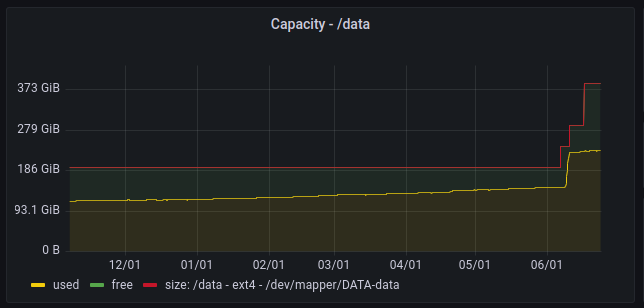
I když jsme po technické stránce schopni tyto nenadálé situace rychle vyřešit, mnohem raději se jim snažíme přecházet. Schválení navýšení výkonu či kapacity „až když je problém“ totiž může ze strany klienta zabrat někdy i dny a taková časová prodleva ohrožuje fungování projektu. Právě proto všechny výše zmíněné metriky pečlivě sledujeme a než vůbec dojde k nějakému problému, aktivně mu předcházíme konzultací s klientem.
Záchranná brzda, pokud selžou ostatní mechanismy. Používáme Pingdom, který posílá HTTP požadavky na monitorované weby. Odesílá je v pravidelných intervalech, střídavě ze svých koncových bodů po celém světě. Většinou na hlavní stránku, volitelně i na další důležité adresy webu.
Kontroluje a zachytí problémy typu:
Díky výše uvedeným nástrojům, nepřetržitému monitoringu a maximálnímu zabezpečení zajišťujeme všem našim klientům stabilní provoz e-shopů, webových stránek nebo intranetů. Veškerá data jsou u nás v bezpečí, a pokud náhodou dojde třeba k nenadálému výpadku, dokážeme okamžitě reagovat.
Hledáte spolehlivého dodavatele pro svůj online projekt? Dejte nám vědět, rádi vám navrhneme ideální řešení.

